During patching for the recent GHOST bug, I updated all packages (including kernel) on a Ubuntu 14.04 file server (filer). This filer provided static content (mainly tens of thousands of images) to a number of web servers. You can see the effect in the following load graph from the filer:
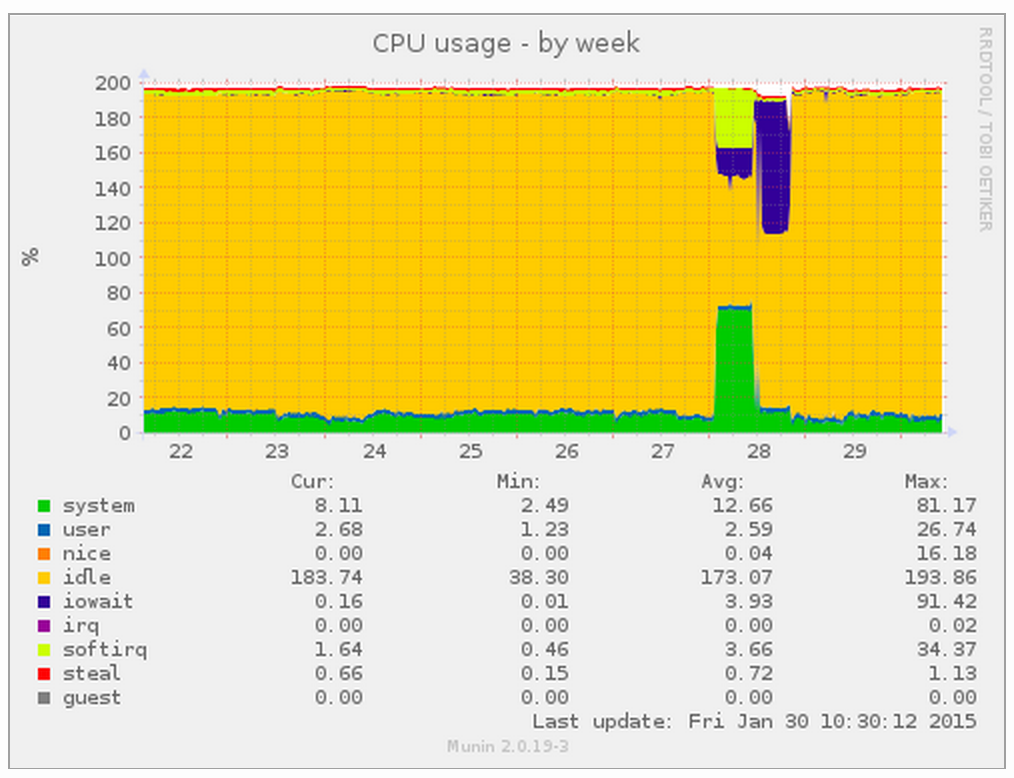
You may notice from the above, that there were actually two issues. The first was solved by upgrading the filer from 14.04 to 14.10 based on a number of online references to symptoms and fixes. About an hour after this upgrade, a new form of NFS slowness manifested and, needless to say, sites that rendered in <1sec were now taking >15secs.
Diagnosing the second issue took a while longer but some tips and utilities include:
- check /var/log and see if any log files are increasing rapidly;
- check top and check any processes with high / unusual utilisation;
- use iostat (apt-get install sysstat) and pay particular attention to any devices with high volumes of transactions per second. In my case it was the root filesystem rather than any of the mounted partitions exported by NFS.
- use iotop (apt-get install iotop) and note any processes with high utilisation (in my case jbd2/xvda1-8 was at 100% and xvda1-8 is my root partition)
The jbd2 process is the ext4 journaling process. At this point you can evaluate fsck’ing your partition but I wanted to see if I could discover what was happening here. I enabled some debugging via:
# enable tracing: echo 1 > /sys/kernel/debug/tracing/events/ext4/ext4_sync_file_enter/enable # wait a couple of seconds and: cat /sys/kernel/debug/tracing/trace # and disable tracing: echo 0 > /sys/kernel/debug/tracing/events/ext4/ext4_sync_file_enter/enable
What I found were lots of:
nfsd-2085 [001] .... 53730942.155573: ext4_sync_file_enter: dev 202,1 ino 276278 parent 149955 datasync 0 nfsd-2071 [001] .... 53730942.158743: ext4_sync_file_enter: dev 202,1 ino 276278 parent 149955 datasync 0 ...
where every entry related to the same inode number (276278). We found this via:
find / -inum 276278 /var/lib/nfs/v4recovery
The solution was to stop nfs_kernal_server, remove that directory entirely, add it back and restart the nfs_kernel_server. We got the permissions wrong on the first attempt but this’ll be obvious from dmesg / kernel log messages such as:
kernel: [53731827.778104] NFSD: Failed to remove expired client state directory 8d97cccceb37641d3804a84683a9282a kernel: [53731827.779204] NFSD: failed to write recovery record (err -13); please check that /var/lib/nfs/v4recovery exists and is writeableNFSD: Failed to remove expired client state directory 8d97cccceb37641d3804a84683a9282a